Kubernetes Application Observer¶
Krake employs self-healing processes on its resources while running. A reconciliation is done on each resource whose status deviates from its specifications. This can happen if a resource has been modified manually, attacked, or if any anomaly occurred on the actual resource that the Krake resource describes.
Reconciliation¶
Overview¶
The reconciliation is the act of bringing the current state of a resource to its desired state. During the course of its life, the real-life pendant of a Krake resource may be updated, and thus differ from the desired state (user-defined). To correct this, Krake performs a reconciliation, and the actual state is “replaced” by the desired state. The Krake Controllers are responsible for actually doing the reconciliation over the resources they manage.
The reconciliation is based on two fields of a resource data structure:
- spec
The specifications of a resource are stored in this attribute. It corresponds to the desired state of this resource.
It has the following properties:
- set and/or updated by the user;
- should not be modified by the Krake controllers, but nothing restricts it (should be limited using RBAC, see Security principles).
- status
The current status of the resource as seen in the real-world are stored in this attribute.
It has the following properties:
- should not be modified by the user, but nothing restricts it (should be limited using RBAC, see Security principles);
- set and/or updated by the Krake controllers.
Important
Resources must have a spec AND a status attribute to be reconciled.
Reconciliation loop¶
The actual reconciliation is done infinitely, during the so-called reconciliation loop. This loop is not necessarily an in-code loop, and can be more of a conceptual loop between different components.
This workflow in Krake for a specific resource is presented on the following figure:
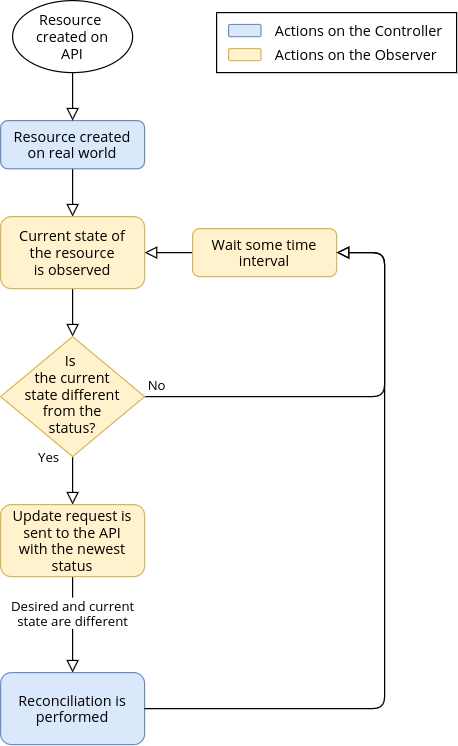
Reconciliation loop in Krake
The workflow is as follows:
- The resource is created on the API;
- The actual resource is created by the Controller in the real-world;
- The Controller responsible for this resources watches, or observes its current state in the real-world. This is the role of the Observer;
- This current state is compared to the
status, stored internally on the Observer; - If the actual state is the same as the
statusof the resource, as stored in the Observer, nothing happens. This workflow is started again from step 3 onwards after a defined time period; - If the actual state is different from the
statusof the resource, it means that the actual resource was modified in the real-world; - The Observer notifies the API, by updating the
statusfield of the resource; - The Controller receives the up-to-date version of the resource, and performs the reconciliation, by applying the desired state on the actual resource;
- The workflow starts again from step 3.
Warning
For the moment, Krake only implements reconciliation loop for the Krake
Application resources of the Kubernetes API.
Kubernetes Application Observer¶
The Krake applications of the Kubernetes API have a dedicated
KubernetesApplicationObserver. For each application which has some actual resources on a
cluster, an observer is created. This KubernetesApplicationObserver watches the status
of all Kubernetes resources present in the application specification.
For instance, the nginx application has a Kubernetes Deployment and a
Service. If a user changes the image version of the container in the Deployment
or a label in the Service, this will be detected by the Kubernetes application
Observer. It will update the status of the application and the Kubernetes Controller
will observe a deviation with the spec and update the actual Deployment and
Service accordingly.
The list of fields which are observed by the Kubernetes application observer can be controlled by specifying a Custom Observer Schema.
This observer schema uses the two fields last_applied_manifest and
last_observed_manifest, both of which can be found in app.status.
last_applied_manifest contains the information about the latest applied data,
which the application should currently be running on. last_observed_manifest
on the other hand contains information about the latest observed manifest state of this
application. By comparing both datasets, the differences between the desired and
observed status can be determined and the corresponding parts can be created, updated or
deleted.
The actual workflow of the Kubernetes Application Observer is as follow:
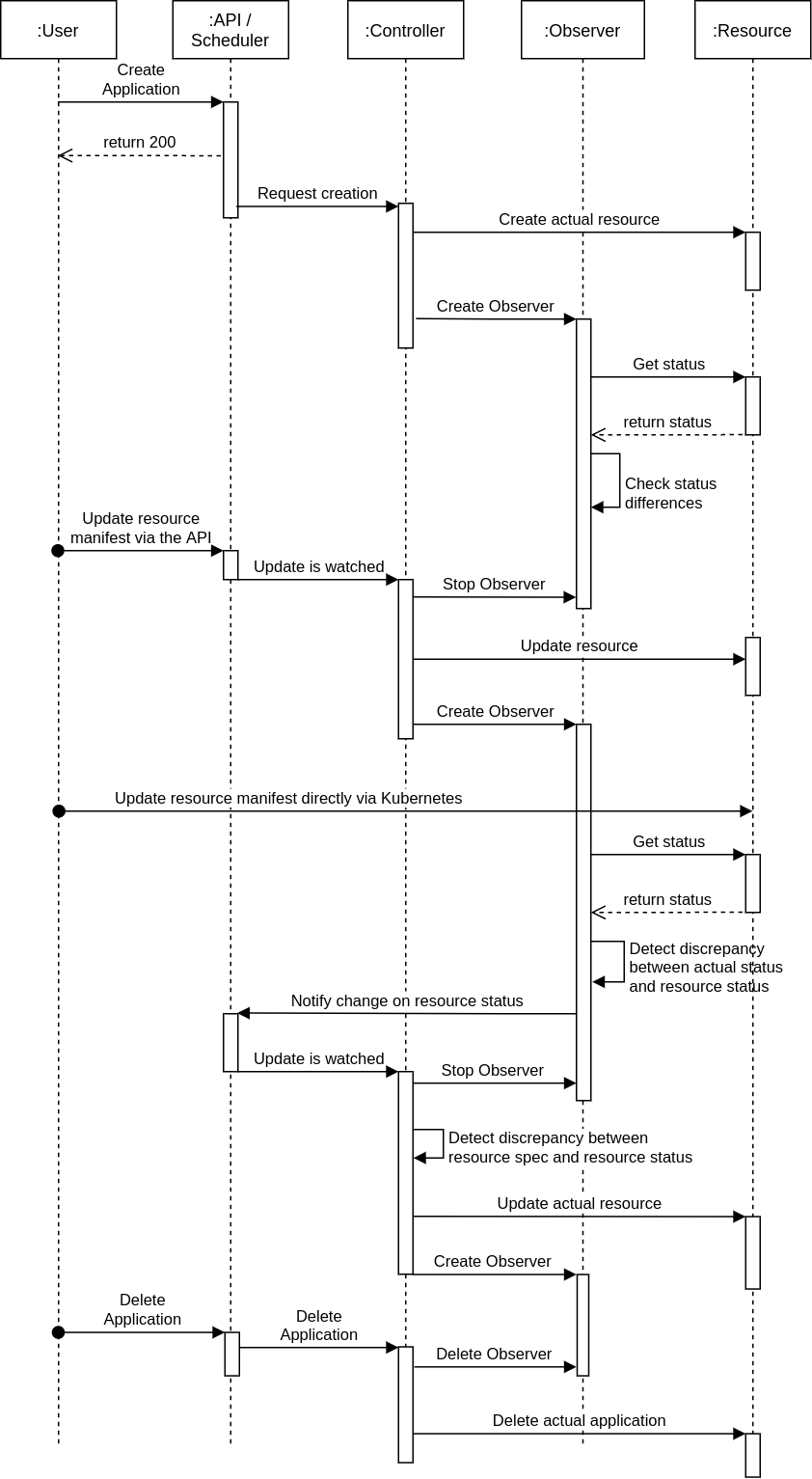
Sequence diagram of the Kubernetes Application Observer lifecycle
Summary¶
Creation¶
After an Application’s resources are created, a Kubernetes Application Observer is also created for this specific Application.
Update¶
Before the Kubernetes resources defined in an Application are updated, its
corresponding Kubernetes Application Observer is stopped. After the update has been
performed, a new observer is started, which observes the newest status of the
Application (the actual Kubernetes resources).
Deletion¶
Before the Kubernetes resources of an Application are deleted, its corresponding KubernetesApplicationObserver is stopped.
Actions on the API side (summary)¶
| Action | Observer stopped before | Observer started after |
|---|---|---|
| Create | No | Yes |
| Update | Yes | Yes |
| Delete | Yes | No |
On status change¶
The KubernetesApplicationObserver periodically checks the current state of its
Application. The status is read and compared to the status field of the Application.
If a Kubernetes resource of the Application changed on its cluster, the
KubernetesApplicationObserver sends an update request to the API, to change its
status field. This field is updated to match what the Observer fetched from the
cluster.
Then the Kubernetes Controller starts processing the update normally: a discrepancy is
found between the desired state (spec) and the current one (status). Thus the
controller reacts and bring back the current state to match the desired one, by
reconciliation. As an update is performed, the observer is stopped before and started
after this reconciliation.
After the reconciliation, the status field of the Application follows now the
desired state. The Kubernetes Application Observer observes this state to check for any
divergence.
Warning
If another resource is added manually (not through Krake) to a cluster managed by Krake, Krake will not be aware of it, and no management of this resource will be performed: no migration, self-healing, updates, etc.