Scheduling¶
This part of the documentation presents the Krake scheduling component and how the Krake resources are handled by the scheduling algorithm.
The Krake scheduler is a standalone controller that processes the following Krake resources:
- Application
- Cluster
- Magnum cluster (Warning: Due to stability and development issues on the side of Magnum, this feature isn’t actively developed anymore.)
The scheduler algorithm selects the “best” backend for each resource based on metrics of the backends and the resource’s constraints and specifications. The following sections describe the application and Magnum cluster handlers of the Krake scheduler.
Application handler¶
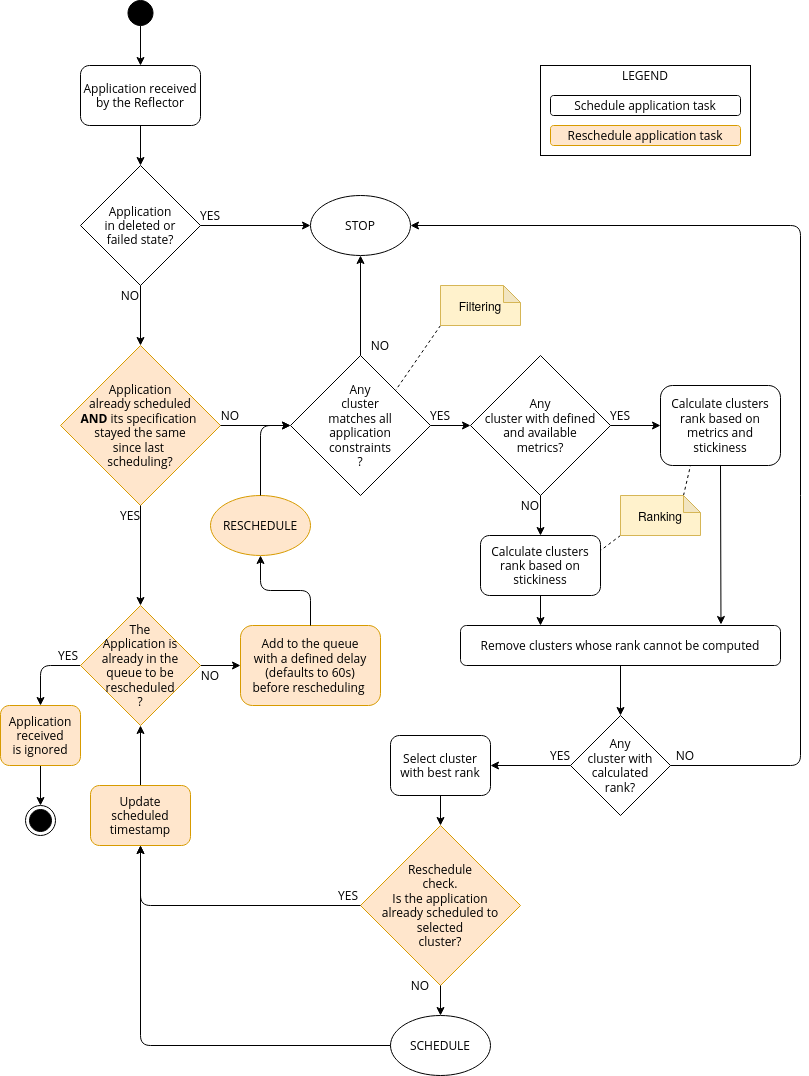
The application handler is responsible for scheduling and rescheduling (automatic migration) of the applications with non-deleted and non-failed states. Applications with deleted or failed state are omitted from the scheduling. Currently, the application handler considers every Kubernetes cluster.
Scheduling of Applications¶
At first, the scheduler checks, if the clusters that will be considered and filtered to host the application, are even ONLINE. If a cluster isn’t reachable, it is not considered in the scheduling process.
The application handler evaluates if all constraints of an application match the available Kubernetes cluster resources. The application constraints define restrictions for the scheduling algorithm. Currently, the custom resources constraint, the cluster label constraint and the metric constraint are supported, see Constraints. This is a first filtering step.
Selected Kubernetes clusters could contain metrics definition. If the cluster contains metrics definition, the application handler fetches metric values from the corresponding metrics providers which should be defined in the metric resource specification, see Metrics and Metrics Providers.
Then, the score for each Kubernetes cluster resource is computed. The cluster score is represented by a decimal number and is computed from Kubernetes cluster stickiness and metric values and weights. More information on stickiness in the Stickiness section. The Kubernetes clusters with defined metrics are preferred. It means clusters which are not linked to any metric have a lower priority than the ones with linked metrics:
- If there are no cluster with metrics: the score is only computed using the stickiness;
- If there are clusters with metrics: the clusters without metrics are filtered out and the scores of the ones with metrics are computed and compared.
This step is a ranking step.
The score formula for a cluster without metrics is defined as follows:
\[score = sticky_{value} \cdot sticky_{weight}\]The score formula for a cluster with n metrics is defined as follows:
\[score = \frac{(sticky_{value} \cdot sticky_{weight}) + \sum\limits_{i=1}^n metric_{value_i} \cdot metric_{weight_i}} {sticky_{weight} + \sum\limits_{i=1}^n metric_{weight_i}}\]
The application is scheduled to the cluster with the highest score. If several clusters have the same score, one of them is chosen randomly.
Rescheduling (automatic migration) of Applications¶
- Applications that were already scheduled are put in the scheduler controller queue again, to be rescheduled later on. Applications will go through the scheduling process again after a certain interval, which is defined globally in the scheduler configuration file, see Configuration (defaults to 60s). This parameter is called reschedule_after. It allows an application to be rescheduled to a more suitable cluster if a better one is found.
Stickiness¶
Stickiness is an extra metric for clusters to make the application “stick” to it by increasing its score. Stickiness extra metric is defined by its value and configurable weight. It represents the cost of migration of an Application, as it is added to the score of the cluster on which the Application is currently running.
If the value is high, no migration will be performed, as the updated score of the current cluster of the Application will be too high compared to the score of the other clusters. If this value is too low, or if this mechanism was not present, any application could be migrated from just the slightest change in the clusters score, which could be induced by small changes in the metrics value. Thus the stickiness acts as a threshold: the changes in the metrics values has to be higher than this value to trigger a rescheduling.
The stickiness weight is defined globally in the scheduler configuration file, see Configuration (defaults to 0.1). If the application is already scheduled to the passed cluster, a cluster stickiness is 1.0 multiplied by the weight, otherwise 0.
Application Handler’s workflow:¶
The following figure gives an overview about the application handler of Krake scheduler.
Special note on updates:¶
kube_controller_triggered:¶
This timestamp is used as a flag to trigger the Kubernetes Controller reconciliation.
Together with modified, it’s allowing correct synchronization between Scheduler and
Controller.
It is updated when the chosen Cluster has changed, or once after the update of an
Application triggered its rescheduling, even if this did not change the scheduled
cluster. The second case mostly occurs when a user updates it through the API.
This timestamp is used to force an Application that has been updated by a user to be
rescheduled before the changes are applied by the Kubernetes Controller. Without this
mechanism, the Application may be updated, but rescheduled somewhere else
afterwards.
The actual workflow is the same as the one explained in the schema above. However, there is an additional interaction with the Kubernetes Controller:
The user updates the
Applicationmy-appon the API:my-app’smodifiedtimestamp is higher than thekube_controller_triggeredtimestamp;The Kubernetes Controller rejects the update on
my-appin this case;The Scheduler accepts the update on
my-appand chooses a cluster for the updatedmy-app;as the cluster changed, the
kube_controller_triggeredtimestamp is updated;my-app’smodifiedtimestamp is lower than thekube_controller_triggeredtimestamp;the updated
my-appis rejected by the Scheduler because of this comparison;the updated
my-appis accepted by the Kubernetes Controller;the actual updates of the
Applicationare performed by the Kubernetes Controller if needed.
When the Application is rescheduled, if the selected cluster did not change, then the
kube_controller_triggered timestamp is updated only if the rescheduling was
triggered by an update of the Application. If the Application is rescheduled on the same
cluster automatically, then the timestamp is not updated. This prevents an update of
each Application on each automatic rescheduling, which would need to be handled by the
Kubernetes controller.
To sum up, the kube_controller_triggered timestamp represent the last time this
version of the Application was scheduled by the Scheduler.
scheduled:¶
The scheduled timestamp expresses the last time the scheduling decision changed for
the current resource. This timestamp does not correspond to the time where the
Application was deployed on the new cluster, just the time where the scheduler updated,
on the Application, the reference to the cluster where it should be deployed. It is
actually updated during a call from the scheduler to the API to change the binding of
the Application.
This timestamp is however not updated if an update of its Application did not lead to a rescheduling, just a re-deployment.
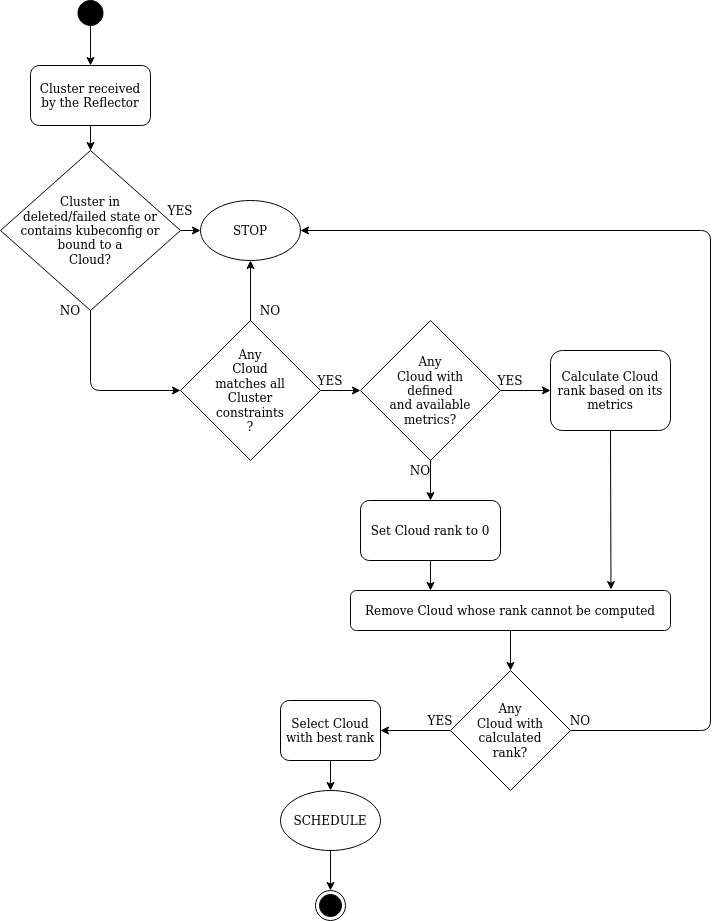
Cluster handler¶
The Cluster handler is responsible for scheduling Kubernetes Clusters to the best cloud backend (currently Krake supports OpenStack as a cloud backend). The Cluster handler should process only Clusters that are not bound to any Cloud, have non-deleted/non-failed state and also the Clusters should not contain the kubeconfig file in their spec. If the Cluster contains the kubeconfig file in its spec it is considered as an existing cluster which was registered or created by Krake and therefore should be ignored by the Cluster handler.
Scheduling of Clusters¶
The Cluster handler evaluates if all the constraints of a Cluster match the available cloud resources. The Cluster constraints define restrictions for the scheduling algorithm. Currently, Cloud label and metrics constraints are supported, see Constraints.
If the selected Cloud resources contain metric definitions, the Cluster handler fetches metric values from the corresponding metrics providers which should be defined in the metric resource specifications, see Metrics and Metrics Providers.
Then, the score for each Cloud resource is computed. The Cloud score is represented by a decimal number and is computed from metric values and weights. If a given Cloud does not contain any metric definition, its score is set to 0. Therefore, the Clouds with defined metrics are preferred:
- If there are no Clouds with metrics: the score is 0 for all Clouds.
- If there are Clouds with metrics: the Clouds without metrics are filtered out and the scores of the ones with metrics are computed and compared.
This step is a ranking step.
The score formula for a Cloud without metrics is defined as follows:
\[score = 0\]The score formula for a Cloud with n metrics is defined as follows:
\[score = \frac{\sum\limits_{i=1}^n metric_{value_i} \cdot metric_{weight_i}} {\sum\limits_{i=1}^n metric_{weight_i}}\]
The Cluster is scheduled to the Cloud with the highest score. If several Clouds have the same score, one of them is chosen randomly.
The following figure gives an overview about the Cluster handler of the Krake scheduler.
Magnum cluster handler¶
Warning
Due to stability and development issues on the side of Magnum, this feature isn’t actively developed anymore.
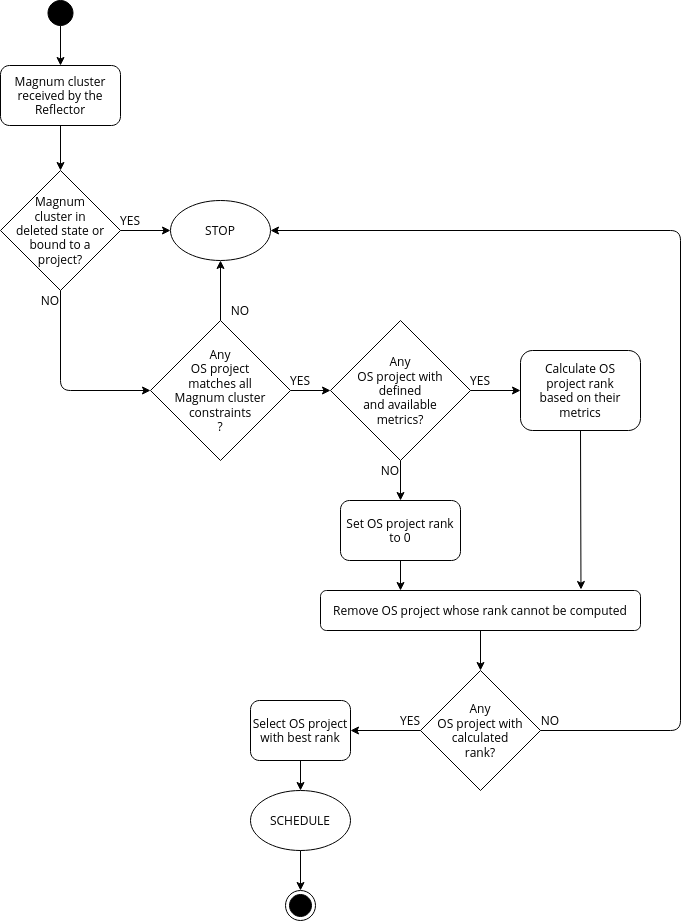
The Magnum cluster handler is responsible for scheduling Magnum clusters to the best OpenStack project. The Magnum cluster handler should process only Magnum clusters that are not bound to any OpenStack project and have non-deleted state. Currently, the Magnum cluster handler considers every OpenStack project.
Scheduling of Magnum clusters¶
The Magnum cluster handler evaluates if all the constraints of a Magnum cluster match the available OpenStack project resources. The Magnum cluster constraints define restrictions for the scheduling algorithm. Currently, only the OpenStack project label constraints are supported, see Constraints. This is a first filtering step.
Selected OpenStack project resources could contain metric definitions. If the OpenStack project contains metrics definition, the Magnum cluster handler fetches metric values from the corresponding metrics providers which should be defined in the metric resource specifications, see Metrics and Metrics Providers.
Then, the score for each OpenStack project resource is computed. The OpenStack project score is represented by a decimal number and is computed from metric values and weights. If a given OpenStack project does not contain metric definition, its score is set to 0. Therefore, the OpenStack projects with defined metrics are preferred:
- If there are no project with metrics: the score is 0 for all projects;
- If there are projects with metrics: the projects without metrics are filtered out and the scores of the ones with metrics are computed and compared.
This step is a ranking step.
The score formula for a OpenStack project without metrics is defined as follows:
\[score = 0\]The score formula for a OpenStack project with n metrics is defined as follows:
\[score = \frac{\sum\limits_{i=1}^n metric_{value_i} \cdot metric_{weight_i}} {\sum\limits_{i=1}^n metric_{weight_i}}\]
The Magnum cluster is scheduled to the OpenStack project with the highest score. If several OpenStack projects have the same score, one of them is chosen randomly.
The following figure gives an overview about the Magnum cluster handler of Krake scheduler. “OS project” means “OpenStack project resource” on the figure.
Metrics and Metrics Providers¶
Overview¶
Warning
Due to stability and development issues on the side of Magnum, this feature isn’t actively developed anymore.
This section describes the metrics and their providers used in the Krake scheduling algorithm.
The Krake scheduler filters backends based on defined backend metrics. The appropriate metrics definition can prioritize the backend as a potential destination for a given resource.
Krake provides two kinds of Metrics and MetricsProviders. GlobalMetric as well as
the GlobalMetricsProvider can be used throughout the entire Krake infrastructure by
all users, apps and clusters. In contrast, the Metric and MetricsProvider object
are bound to a namespace (hence why they’re called ‘namespaced’) and can only be used in
their respective context. In most of the documentation chapters, only GlobalMetrics
are talked about, but namespaced Metrics can also be used to follow these sections.
The metrics for the Kubernetes clusters, Magnum clusters and OpenStack projects
resources are defined by the -m or --metric option in the rok CLI, see
Rok documentation. Multiple metrics can be specified for
one resource with the following syntax: <name> <weight>.
Examples:
# Kubernetes clusters:
rok kube cluster create <kubeconfig> --global-metric heat_demand_zone_1 0.45
# Magnum clusters:
rok os cluster create <cluster_name> --metric heat_demand_zone_1 54
# OpenStack projects:
rok os project create --user-id $OS_USER_ID --template $TEMPLATE_ID my-project --metric heat_demand_zone_1 3
By design, the general Krake metric resource (called GlobalMetric) is a core api
object, that contains its value normalization interval (min, max) and metrics provider
name, from which the metric current value should be requested. For the moment, Krake
supports the following types of metrics providers:
- Prometheus metrics provider, which can be used to fetch the current value of a metric from a Prometheus server;
- Kafka metrics provider, which can be used to fetch the current value of a metric from a KSQL database;
- Static metrics provider, which returns always the same value when a metric is fetched. Different metrics can be configured to be given by a Static provider, each with their respective value. The static provider was mostly designed for testing purposes.
The metrics provider is defined as a core api resource (called
GlobalMetricsProvider) that stores the access information for the case of a
Prometheus metrics provider, or the metrics values for the case of a Static
metrics provider.
Example¶
api: core
kind: GlobalMetric
metadata:
name: heat_demand_zone_1 # name as stored in Krake API (for management purposes)
spec:
max: 5.0
min: 0.0
provider:
metric: heat_demand_zone_1 # name on the provider
name: <metrics provider name> # for instance prometheus or static_provider
---
# Prometheus metrics provider
api: core
kind: GlobalMetricsProvider
metadata:
name: prometheus_provider
spec:
type: prometheus # specify here the type of metrics provider
prometheus:
url: http://localhost:9090
---
# Kafka metrics provider
api: core
kind: GlobalMetricsProvider
metadata:
name: kafka_provider
spec:
type: kafka
kafka:
comparison_column: my_comp_col # Name of the column where the metrics names are stored
table: my_table # Name of the table in which the metrics are stored
url: http://localhost:8080
value_column: my_value_col # Name of the column where the metrics values are stored
---
# Static metrics provider
api: core
kind: GlobalMetricsProvider
metadata:
name: static_provider
spec:
type: static # specify here the type of metrics provider
static:
metrics:
heat_demand_zone_1: 0.9
electricity_cost_1: 0.1
In the example above, all metrics providers could be used to fetch the
heat_demand_zone_1 metric. By specifying a name in spec.provider.name of the
GlobalMetric resource, the value would be fetched from a different provider:
prometheus_providerfor the Prometheus provider;kafka_providerfor the Kafka provider;static_providerfor the Static provider (and the metric would always have the value0.9).
Note
A metric contains two “names”, but they can be different. metadata.name is the
name of the GlobalMetric resource as stored by the Krake API. In the database,
there can not be two resources of the same kind with the exact same name.
However (if we take for instance the case of Prometheus), two metrics, taken from
two different Prometheus servers could have the exact same name. This name is given
by spec.provider.metric.
So two Krake GlobalMetric`s resources could be called ``latency_from_A` and
latency_from_B in the database, but their name could
be latency in both Prometheus servers.
The Krake metrics and metrics providers definitions can also be added directly to the Krake etcd database using the script krake_bootstrap_db, instead of using the API, see Bootstrapping.
Constraints¶
This section describes the resource constraints definition used in the Krake scheduling algorithm.
The Krake scheduler filters appropriate backends based on defined resource constraints. A backend can be accepted by the scheduler as a potential destination for a given resource only if it matches all defined resource constraints.
The Krake scheduler supports the following resource constraints:
- Label constraints
- Metric constraints
- Custom resources constraints
The Krake users are allowed to define these restrictions for the scheduling algorithm of Krake.
The following sections describe the supported constraints of the Krake scheduler in more detail.
Label constraints¶
Krake allows the user to define a label constraint and to restrict the deployment of resources only to backends that matches all defined labels. Based on the resource, Krake supports the following label constraints:
- The Cluster label constraints for the Application resource
- The Cloud label constraints for the Cluster resource
- The OpenStack project label constraints for the Magnum Cluster resource (Warning: Due to stability and development issues on the side of Magnum, this feature isn’t actively developed anymore.)
A simple language for expressing label constraints is used. The following operations can be expressed:
- equality
The value of a label must be equal to a specific value:
<label> is <value> <label> = <value> <label> == <value>- non-equality
The value of a label must not be equal to a specific value:
<label> is not <value> <label> != <value>- inclusion
The value of a label must be inside a set of values:
<label> in (<value>, <value>, ...)- exclusion
The value of a label must not be inside a set of values:
<label> not in (<value>, <value>, ...)
The Cluster label constraints for the Application and Cluster resources
are defined by -L (or --cluster-label-constraint, --cloud-label-constraint) option in the
rok CLI, see Rok documentation. The constraints can be
specified multiple times with the syntax: <label> expression <value>.
Examples:
# Application
rok kube app create <application_name> -f <path_to_manifest> -L 'location is DE'
# Cluster:
rok kube cluster create <cluster_name> -f <path_to_tosca> -L 'location is DE' ...
Metric constraints¶
Krake allows the user to define a metric constraint and to restrict the deployment of resources only to backends that matches the metric constraint. Based on the resource, Krake supports the following metric constraints:
- The Cluster metric constraints for the Application resource
- The Cloud metric constraints for the Cluster resource
A simple language for expressing metric constraints is used. The following operations can be expressed:
- equality
The value of a label must be equal to a specific value:
<metric> is <value> <metric> = <value> <metric> == <value>- non-equality
The value of a metric must not be equal to a specific value:
<metric> is not <value> <metric> != <value>- greater than
The value of a metric must be greater than a specific value:
<metric> greater than <value> <metric> gt <value> <metric> > <value>- greater than or equal
The value of a metric must be greater or equal than a specific value:
<metric> greater than or equal <value> <metric> gte <value> <metric> >= <value> <metric> => <value>- less than
The value of a metric must be less than a specific value:
<metric> less than <value> <metric> lt <value> <metric> < <value>- less than or equal
The value of a metric must be less or equal than a specific value:
<metric> less than or equal <value> <metric> lte <value> <metric> <= <value> <metric> =< <value>
The metric label constraints for the Application and Cluster resources are defined
by -M (or --cluster-metric-constraint, --cloud-metric-constraint) option in the rok CLI,
see Rok documentation. The constraints can be
specified multiple times with the syntax: <metric> expression <value>.
Examples:
# Application
rok kube app create <application_name> -f <path_to_manifest> -M 'load = 5'
# Cluster
rok kube cluster create <cluster_name> -f <path_to_tosca> -M 'load = 5' ...
Custom resources:¶
Krake allows the user to deploy an application that uses Kubernetes Custom Resources (CR).
The user can define which CRs are available on his cluster. A CR is defined
by the Custom Resource Definition (CRD) and Krake uses this CRD name with the format
<plural>.<group> as a marker.
The supported CRD names are defined by -R or --custom-resource option in rok
CLI. See also Rok documentation.
Example:
rok kube cluster create <kubeconfig> --custom-resource <plural>.<group>
Applications that are based on a CR have to be explicitly labeled with a cluster resource constraint. This is used in the Krake scheduling algorithm to select an appropriate cluster where the CR is supported.
Cluster resource constraints are defined by a CRD name with the
format <plural>.<group> using -R or --cluster-resource-constraint option in
rok CLI. See also Rok documentation.
Example:
rok kube app create <application_name> -f <path_to_manifest> --cluster-resource-constraint <plural>.<group>