Architecture¶
This chapters gives a high-level overview about the software architecture of Krake. The following figure gives an overview about the components of Krake. The components are described in more detail in the following sections.
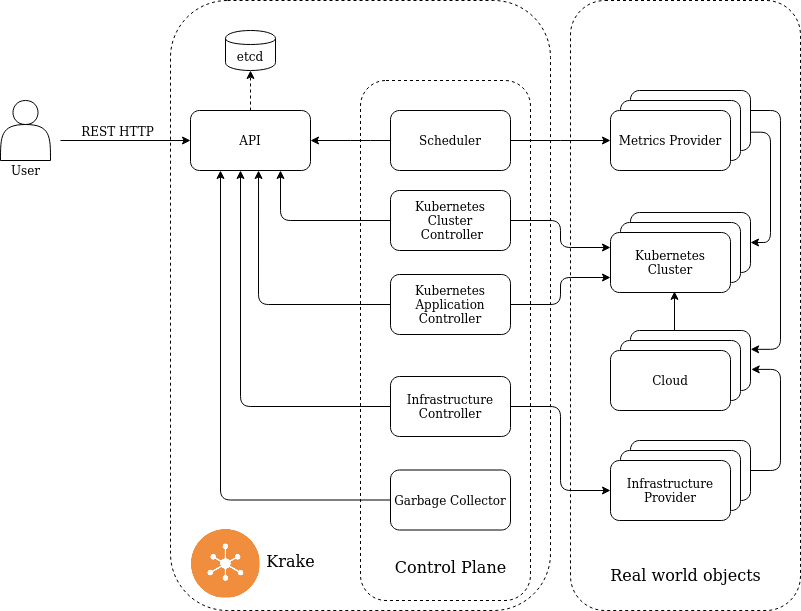
Krake components
API¶
The API is the central component of Krake. It holds the global state of the system. Krake uses an abstraction for real world objects – e.g. Kubernetes clusters or clouds (e.g. OpenStack) – managed or used by it. The objects are represented as RESTful HTTP resources called API resources. These resources are stored in an associated etcd database. Each resource is a nested JSON object following some conventions that can be found in section API Conventions.
The API is declarative: instead of sending commands one-by-one to the infrastructure, the user just defines a desired end state, telling the infrastructure exactly how it should look like. Then, the Control Plane works in sync with the infrastructure to find the best way to get there. This means that the actual control flow is not exposed to the user.
Control Plane¶
The control plane is responsible for bringing the declarative API to life: it synchronizes the declared desired state of a API resource with the managed real world object (see also Control Plane on the concepts chapter).
The control plane consists of a set of controllers. Normally, one controller is responsible for one kind of resource, e.g. the Kubernetes Application controller manages Kubernetes Application resources. Only API resources with a changing state are managed by a controller.
System-level tasks are also handled by controllers:
- Garbage Collector
- Resources can depend on other resources. If an API resource is deleted, dependents of the resource are also deleted automatically. This is called cascading deletion. The garbage collector is the controller responsible for executing the cascading deletion (see Garbage Collection for more details).
- Infrastructure Controller
- The infrastructure controller performs life-cycle management of the real-world Kubernetes clusters. (see Infrastructure Controller for more details).
- Scheduler
The scheduler is a very important controller responsible for binding applications – high-level API resources for executing workloads – to a platform managed by Krake.
Tip
For example, the scheduler binds Kubernetes applications to Kubernetes clusters or selects clouds (e.g. OpenStack) for creating new Kubernetes clusters.
The scheduler makes its decision based on a set of metrics provided by external metrics providers (see Scheduling for more details) as well as the availability of the clusters. The decisions are periodically reevaluated, which could potentially lead to migration of applications.
Control Loop¶
The following figure describes the basic control loop that is executed by any controller.
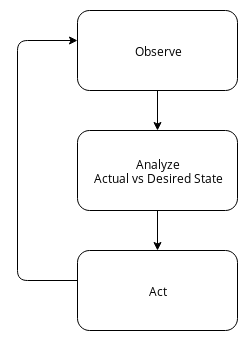
Operator Pattern
The observation of an API resource is done via watching, a long running HTTP request to the API notifying about changes of resources:
$ curl http://localhost:8080/kubernetes/namespaces/testing/applications?watch
{"type": "UPDATED", "object": {"metadata": …, "spec": …, "status": …}}
{"type": "DELETED", "object": {"metadata": …, "spec": …, "status": …}}
{"type": "UPDATED", "object": {"metadata": …, "spec": …, "status": …}}
…
Controller will read this feed, evaluate differences between the desired state and the state of the managed real world object, act accordingly to this difference and update the status of the resource.