Garbage Collection¶
This part of the documentation presents the Garbage Collector component, and how the deletion of resources that others depends on is handled.
Dependency mechanism¶
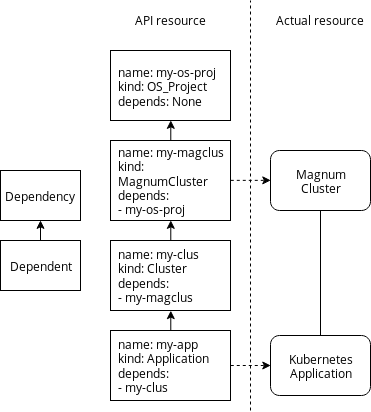
Dependency relationships in Krake with examples.
In Krake, any resource can depend on any other. In this case, we say the dependent depends on the dependency. For instance, a Kubernetes Application depends on a Cluster. We also say that the Cluster owns the Application. The Cluster is one of the owners of the Application in this case.
Every resource with metadata holds a list of its owners. However, no resource holds the list of its owned resources. This is similar to the principle of relational database for instance, with the foreign key mechanism.
In the preceding diagram, a my-app Application is owned by a cluster (see
its list of owners) itself belonging to a Magnum cluster. The latter is
finally owned by an OpenStack project. The project has no dependency, thus its
owner list is empty.
Overview¶
The Garbage Collector is a Controller of Krake and is, as such, to be started independently from the other components of Krake.
“Marked as deleted” vs “to delete” vs “deleted”¶
The resources processed during garbage collection have three different states.
They use the "cascade_deletion" finalizer.
- “Marked as deleted”
A resource is marked as deleted by the API, when the “delete” action is called on this resource. It means two things for the resource object:
- the
deletedtimestamp of the metadata is set to the current time; - the
"cascade_deletion"finalizer is added to its list of finalizer.
A resource marked for deletion enters then the garbage collection process.
Caution
This state is irreversible. A resource that enters this state will be processed by the garbage collector, only to be deleted in the end of garbage collection process.
- the
- “To delete”
A resource is said to be in the “to delete” state if two conditions are met :
- its
deletedtimestamp is set; - it has no finalizer.
Such a resource can still be transferred by the components. If a resource in this state is received by the API on update, it is deleted.
- its
- “Deleted”
- A deleted resource is completely removed from the database. A last “DELETED” event can be watched on the API when the actual deletion occurs to act on the deletion but the resource itself must be considered erased, and not managed by the API anymore.
Role of the Garbage Collector¶
The role of the Garbage Collector is to handle resources marked as deleted by the API, but not yet deleted.
When a resource is received, the garbage collector has to:
- update its dependency graph (see Dependency graph);
- get the resources that directly depend on it;
- call the API with the “delete” action to let it mark the dependents as deleted;
- if a resource has no dependent, remove the
"cascade_deletion"finalizer from it, and call the API to update the resource. The resource enters the “to delete” state.
So the role of the Garbage Collector is mostly to get the dependents of a resource, and update them to mark them as deleted. This information is taken from the dependency graph present on the garbage collector, see the Dependency graph section.
Role of the API¶
For the deletion of resources, the garbage collector works tightly with the API, as the garbage collector has no direct access to any resource on the database.
The API is then responsible for:
- actually marking the requested resources as deleted;
- completely deleting a resource from the database during an update, if the resource is in a “to delete” state.
So the API is the one that actually modifies and process the stored resources.
Garbage collection workflow¶
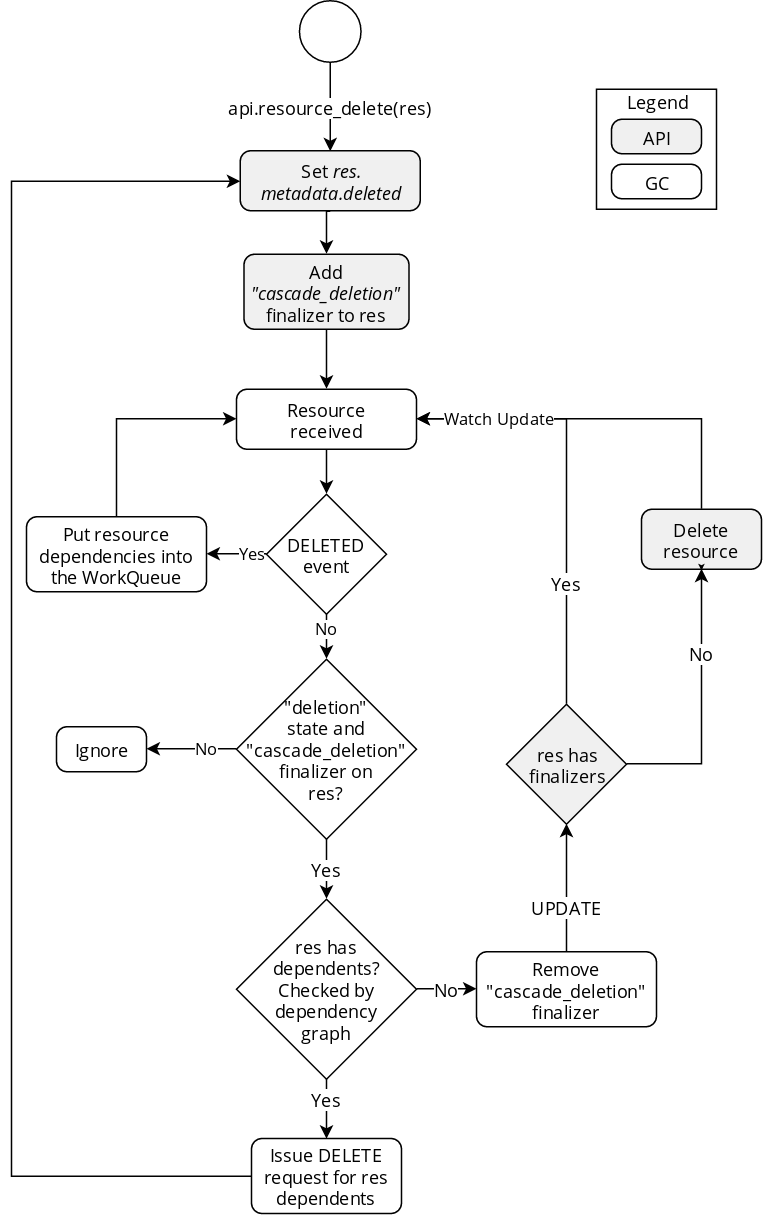
Garbage collection workflow, and communication between the garbage collector and the API
The exact workflow of a resource that the user wants to delete is presented on the previous diagram. Let us take for example an Application A, with a cluster C as single owner.
- A and C were created beforehand, thus they are already present in the dependency graph of the garbage collector;
- the user requests the deletion of the Cluster C, for instance with the
Rok utility or using
curl; - the request is received by the API. The API marks the cluster C as
deleted, and an
UPDATEevent is triggered; - the garbage collector receives the event. It accepts to handle the cluster, as it is marked for deletion;
- the list of dependents of C is fetched from the dependency graph stored on the garbage collector. The garbage collector issues for each of them a “delete” call to the API. In our case, the Application A is the only dependent of C;
- the API receives the call and marks A as deleted. A is updated, and
an
UPDATEevent is triggered; - the garbage collector receives the event, and accepts to handle A;
- A has no dependent, so its
"cascade_deletion"finalizer is removed. An “update” request is sent to the API with the new A; - the API receives the “update” request, with A being in the “to delete”
state. A is deleted from the database. A
DELETEDevent is triggered; - the garbage collector receives the event. A is removed from the dependency graph. The dependencies of A are put in the worker queue of the garbage collector to be handled. The owners are collected from the dependency graph. In our case, C is added to the worker queue;
- C is handled by the garbage collector a second time. It has no dependent
this time, as A has been deleted and removed from the dependency graph.
Thus, the garbage collector removes the
"cascade_deletion"finalizer and issues an “update” call to the API for C; - the API receives the “update” request, with C being in the “to delete”
state. C is deleted from the database. A
DELETEDevent is triggered. C had no dependency, so the garbage collector does not take any action.
Dependency graph¶
Description and goal¶
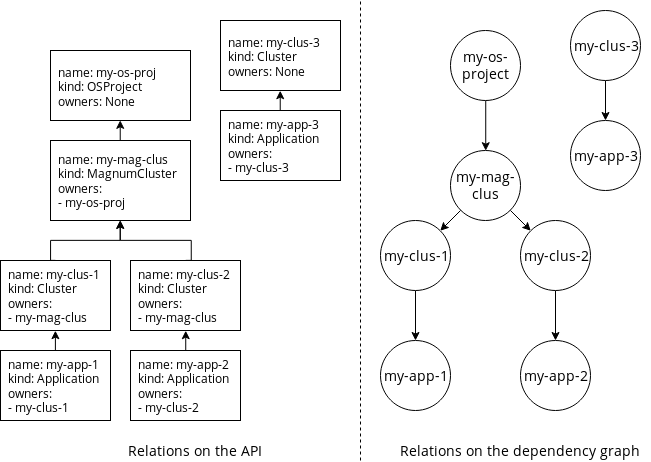
Comparison example of the dependencies, as represented in the API and on the dependency graph.
The dependency graph is an acyclic directed graph stored on the garbage collector as “cache”. Its goal is to store the dependency relationships of all resources managed by the API. The graph is updated when starting the garbage collector, while listing resources, or on events triggered by the API. It is only stored in memory, and is re-created each time the garbage collector is started.
The dependency graph allows the garbage collector to access the dependents of any resource. Otherwise, to get the dependents of a resource, the garbage collector would need to request all resources on the database, and check which one of them have the resource to delete as owner. This would mean of course that all resources of the database would be looped through. This is definitely not optimal and is avoided with the dependency graph.
On the nodes, the graph stores the krake.data.core.ResourceRef object
corresponding to a resource. The edges are directed link from a ResourceRef
object, to the dependencies of the original object.
krake.data.core.ResourceRef objects are used because they can be keys
in dictionaries, whereas normal resources cannot. The reference to the complete
resources is still stored in the graph.
Graph workflow¶
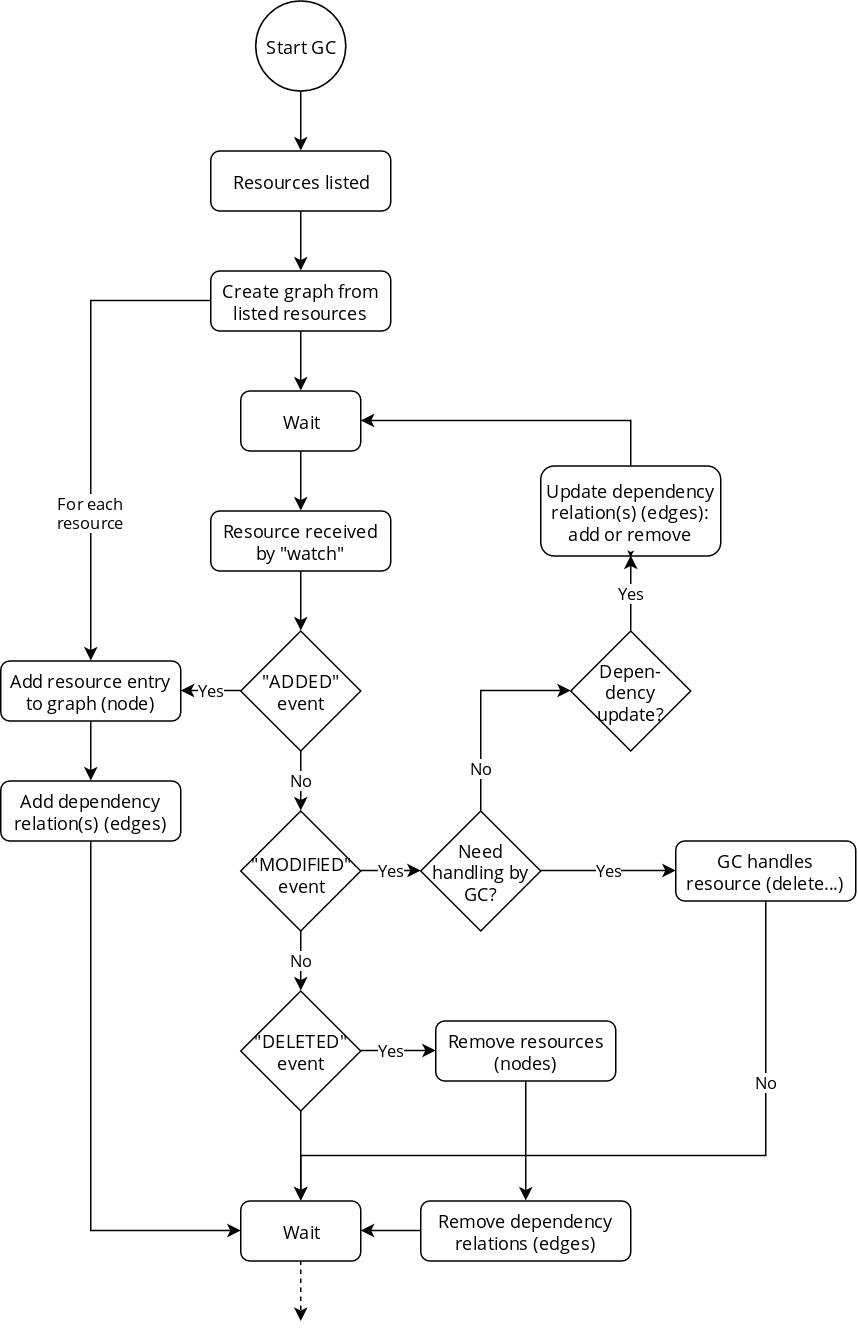
Dependency graph workflow on the garbage collector
Five actions can be performed on the dependency graph: adding, updating or removing a resource, get the dependents of a resource, or get its dependencies.
- Adding a resource:
- Action performed when the garbage collector lists the resources on startup, or when an “ADDED” event is triggered. The resource is added to the graph as node, along with its dependency relations as edges;
- Updating a resource:
- Action performed when an “UPDATED” event is triggered. If the resource dependency relations were modified, the graph edges are modified. The node corresponding to the resource is modified.
- Removing a resource:
- Action performed when a “DELETED” event is triggered. The resource’s corresponding node is removed from the graph, along with the edges bound to it.
- Get the dependents of a resource:
- Action performed by the garbage collector, to know which resource to mark for deletion, without having to reach the API. The nodes on the edges of the resource are listed and returned.
- Get the dependencies of a resource:
- Action performed by the garbage collector, to put the owners of a resource in the worker queue. The owners stored on the resource are returned.