Kubernetes Cluster Observer¶
Krake constantly observes the status of its registered or created clusters while running. For each cluster a separate Kubernetes cluster observer is created. This cluster specific observer calls the Kubernetes API of the real world Kubernetes Cluster periodically. The current status of each cluster is saved in the database of Krake. If a status change of the real world Kubernetes Cluster is detected, Krake updates the saved state of the registered Kubernetes cluster which is stored in its database. Changes in the state of a cluster may be related to Krake being able to connect to the real Kubernetes cluster or not, an unhealthy real world Kubernetes cluster, or metrics providers failing.
Kubernetes Cluster Status Polling¶
Overview¶
The polling is the act of calling the Kubernetes API of the real world Kubernetes
cluster to get its state. During the course of its life, the real-life pendant of a
Krake resource may be updated, and thus differ from the desired state (user-defined). To
correct this, Krake performs a reconciliation, and the actual state is “replaced” by the
desired state. The Krake Controllers are responsible for actually doing the
reconciliation over the resources they manage.
Polling¶
The actual polling is done infinitely, during the so-called polling loop.
This workflow in Krake for a specific resource is presented on the following figure:
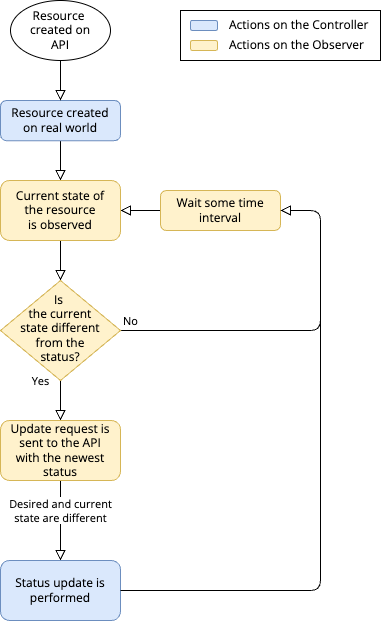
KubernetesClusterObserver polling loop
The workflow is as follows:
- The actual real-world cluster is registered or created by Krake;
- The Kubernetes cluster controller watches, or observes the clusters current
statusin the real-world. This is the role of the KubernetesClusterObserver. This is done by polling thestatuswith a call on the Kubernetes cluster API. - This current state is compared to the
status, stored internally on the Observer; - If the actual state is the same as the
statusof the resource, as stored in the Observer, nothing happens. This workflow is started again from step 3 onwards after a defined time period; - If the actual state is different from the
statusof the resource, it means that the actual cluster was modified in the real-world; - The Observer notifies the Krake API, by updating the
statusfield of the cluster; - The workflow starts again from step 3.
States¶
A Kubernetes cluster watched by it’s corresponding KubernetesClusterObserver can have the following observer related states:
- PENDING
- CONNECTING
- ONLINE
- DEGRADED
- OFFLINE
- UNHEALTHY
- NOTREADY
- FAILING_METRICS
Note
Refer to the States for the infrastructure related cluster states.
PENDING- This state is initially set when a Kubernetes cluster is registered in Krake.
CONNECTING- It is set by the Kubernetes Cluster Observer if the previous state of a cluster was OFFLINE, but the real cluster is available again. In this case, a reconnection is attempted with a temporary CONNECTING state.
ONLINE- If the cluster is reachable in the real world, is in a healthy state and is ready, the status of the cluster in Krake will be ONLINE.
DEGRADED- A cluster will be DEGRADED if the handling of the cluster was not successful, but
the number of retries is not yet exhausted. This is the intermediate state before
being OFFLINE (or back ONLINE). The behaviour is specified with the parameters
backoff(multiplier added to retry attempts, defaults to 1),backoff_delay(number of seconds between retry attempts) andbackoff_limit(number of retries, defaults to -1(infinite)). So if not changed, the cluster will remain in DEGRADED state until the handling was successful. Otherwise, if the number of retries is exhausted, the cluster will transfer to OFFLINE. OFFLINE- If the real world cluster cannot be reached by polling the Kubernetes cluster API, the status of the cluster in Krake will be OFFLINE. This can happen due to several reasons, e.g. the Kubernetes cluster itself is down, network connectivity issues or incorrect configuration of the used kubeconfig file to register the cluster in Krake.
UNHEALTHY- This state is set for clusters in Krake when the Kubernetes API call responds with either PIDPressure, DiskPressure, or MemoryPressure.
NOTREADY- This status is displayed when there is an internal problem in the real Kubernetes cluster. When this status is displayed, an investigation of the Kubernetes cluster itself is highly recommended. The reasons for this status vary, for example, the real Kubernetes cluster’s kubelet is not working properly or other services have failed to start.
FAILING_METRICS- This status is set internally by Krake if a metrics provider is not reachable by Krake and thus metrics cannot be passed correctly into Krake.
Node Health¶
The cluster observer collects health data of a kubernetes cluster and formats it. Data is divided according to the nodes of the cluster and the different pressure types PID, memory and disk. They represent the problems that a kubernetes node could experience, either missing process ids due to too many process instances, memory overload or non-available disk space. These information can be found by calling:
rok kube cluster get X
+-----------------------+---------------------+
| ... | ... |
| nodes | 3/3 |
| nodes_pid_pressure | 0/3 |
| nodes_memory_pressure | 0/3 |
| nodes_disk_pressure | 0/3 |
| ... | ... |
+-----------------------+---------------------+
Nodes are shown according to their health, so 3/3 if all nodes are healthy, and the pressure parameters only get filled, if there is a current problem with one (or more) of the nodes.
Summary¶
Creation¶
After a Cluster resource was registered or successfully created, a KubernetesClusterObserver is also created for this specific cluster.
Update¶
Before the Kubernetes cluster in Krake is updated, its
corresponding KubernetesClusterObserver is stopped. After the update has been performed,
a new observer is started, which observes the newest status of the cluster (the
actual Kubernetes cluster).
Deletion¶
Before the Kubernetes cluster is deleted, its corresponding KubernetesClusterObserver is stopped.
Actions on the API side (summary)¶
| Action | Observer stopped before | Observer started after |
|---|---|---|
| Create | No | Yes |
| Update | Yes | Yes |
| Delete | Yes | No |
On status change¶
The KubernetesClusterObserver periodically checks the current state of its cluster.
The status is read and compared to the status field of the cluster.
If a Kubernetes cluster changed, the KubernetesClusterObserver sends an update request
to the API, to change its status field. This field is updated to match what the
Observer fetched from the cluster.
Then the Kubernetes Cluster Controller starts processing the update normally.
Warning
Currently only Kubernetes clusters which have been registered in Krake or
created by Krake can be observed.